The Step Above Chat-GPT Wrappers

All product managers worth their salt has understood the basics of large-language-models (LLMs). It is a new way to interface with information, and it opens a lot of door which weren’t easy to go through before. Then, the good PMs realize that the average users of LLMs are awful. They try some prompt, it generates some awful generic output with factual errors. So they come up with the idea; if I take OpenAI’s API, feed it some actually good well-tested prompts, I can sell it to both users and investors as the new hot AI startup and make $millions. Pretty smart.
Now here we are. Infinite AI startups, 90% just chat-GPT wrappers with a stripe billing plan. And a $10 million valuation. The product world then responds saying “AI products are fugazis”.
But I don’t believe so. I believe it is just so easy to get going, and most that start in the AI space haven’t really studied how good it could be. Enter: AI Agents. Sophisticated. Tailored to solve real problems. Chained. Prompts are monologues. Multi-agents are more like cross-functional software teams.
The shift happening in AI right now is that we’re finally treating these systems like complex tools instead of crystal balls. The best frameworks, LangGraph, Google ADK, n8n are all converging on the same playbook: plan the work, route the work, do the work, check the work. Exactly what we expect from a real product team. It is very cool.
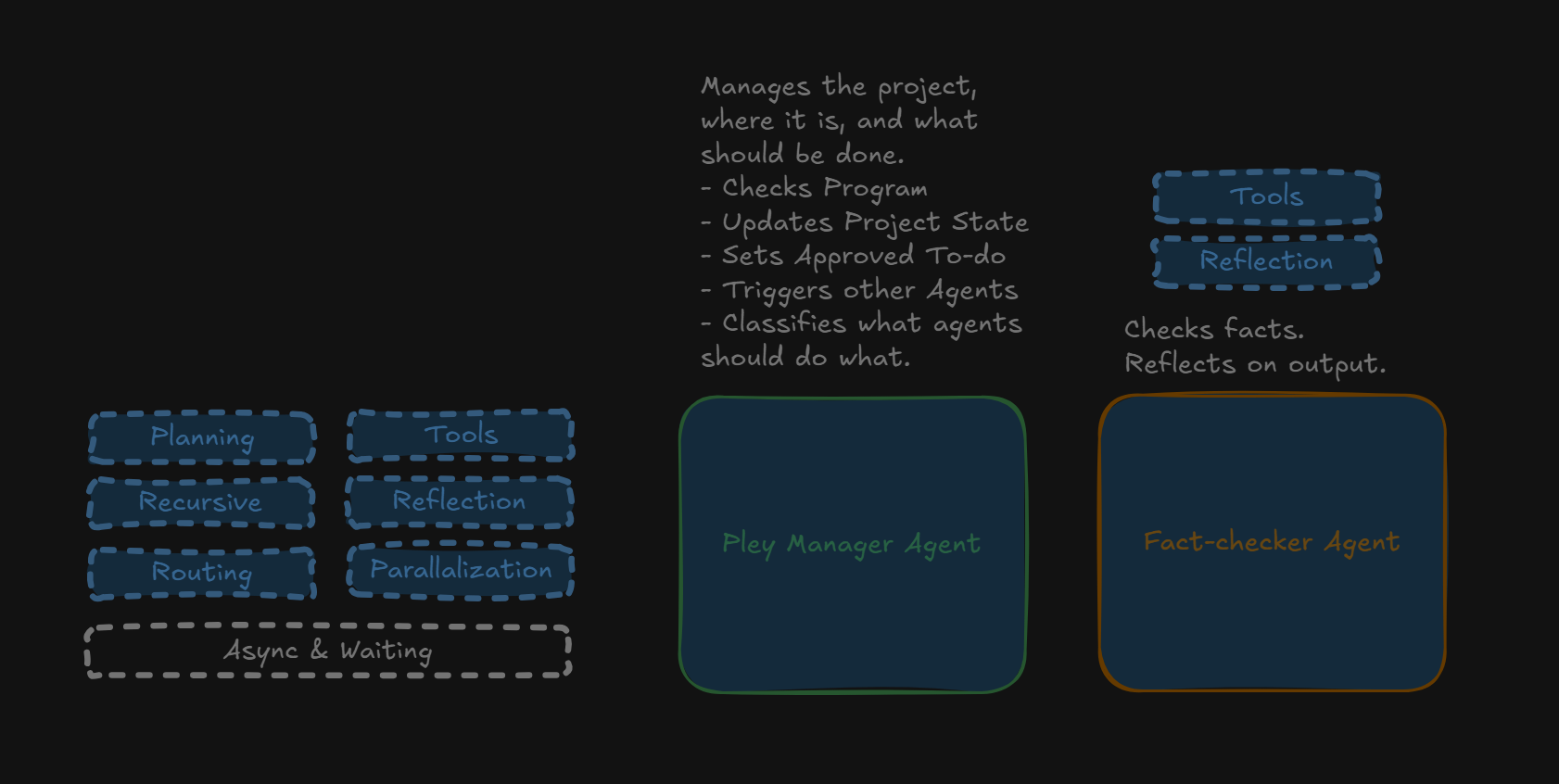
The Pieces that makes GPT-wrappers into something sophisticated
Let’s begin by going through some key terms.
Prompt Chaining. Split complex prompts into multiple steps, avoiding breakdowns, each steps output feeding into then next input. By chaining prompts (one LLM feeds into another), we avoid context-rot when prompts become complicated.
Routing. Have an LLM analyze the user query to determine what steps should be done. Then define those steps, and trigger them with the correct input. Effectively a project manager who knows which agent should do what.
Parallelization. Run multiple agents at the same time if they aren’t dependent on each other. Effectively, it is multiple team members (agents) working on different problems at the same time. It speeds up output by up to a magnitude.
Reflection. A different model takes the output of a first, and compares it to some desired outcome. Example can be an agent which makes sure that the output is in the right format (did the writing agent mess up), or an agent which validates facts using the internet (did another agent hallucinate). Perfomance has been shown to be much higher if it is a different model who does the quality assurance (without the original context).
Planning. This was the game-changer for Cursor and my #1 LLM advice before it became core to all the reasoning models. (1) Break down the job into sub tasks, (2) review it and ask follow up questions if needed, (3) do the work. By planning before executing, the model hits the right output MUCH more often.
Recursion. Allow models to call themselves with an input if the output isn’t up to par. Can also be used in a multi-model setup where two models call each other recursively (Model A outputs, model B reviews and calls Model A.)
Tools. Give the agent access to search engines, APIs, database calls, etc.
Multi-agent. Chain multiple of these together into a big flow.
What is Context Rot?
“Context rot” is a hard-to-define issue in language models where performance degrades as context grows. Even for strong xontext-benchmarking setups like RULER works great even in massive contexts, but you’ll still notice models seeming to “get dumber” in extended chats or large code histories. Try chatting with the same instance of Chat GPT for 100+ messages about the same topic, and watch it derail. It’s a familiar but poorly measurable failure mode. A proposed fix is to split large contexts into smaller model calls and merge results, the idea behind a recursive language model.
Prompt Wrappers Aren’t Products
Every time I see a “ChatGPT wrapper” pitch, it’s the same story: they glued a nice UI on top of one prompt and called it software. I am not hating, a focused prompt can ship a useful feature. But it absolutely collapses the moment you ask it to juggle research, planning, 10 back-and-fourth prompts, and execution. Context rot sets in and output becomes garbage. The context window fills up, focus drift, and suddenly you’re copy-pasting half its output into Google to fact check hallucinations.
If you want enough reliability to develop a complex product, you have to turn the ever-growing prompt into a pipeline, where each step can be troubleshot and improved as a unit. Break down the steps. Treat each one as a contract the next step can trust, just like abstract layers in software development.
- Break down the task into subtasks.
- Ask follow up questions about anything unclear.
- Research the problem.
- Summarize what matters.
- Draft an answer.
- Review the draft with a second pass.
Basic? Yes. Predictable? Also yes. Predictability is the only reason you can debug an agent rather than pray.
Let the System Route Itself
Here’s the painful truth I tell every team: if your “AI assistant” can’t decide what to do next, it’s still a chat GPT FAQ bot. Users can read documentation themselves. Even more, they can copy your docs into any of the 50 AI services they use. Routing is the foundation to break away from just being a “input prompt -> output”-wrapper. The agent needs to look at the request, pick the right tool or workflow, and hand it off. That can be rule-based (“Prompt contains word X, so do Y”), embedding-based (semantic), or LLM-based (flexible, but needs guardrails. “User asked something about X, so do Y”). The important part is that you don’t hardcode every branch. You let the system choose its own path, just like you trust a PM to know when to talk to research, data, engineering, or finance when needed (and more importantly, when not to).
- “Check my order status” routes to the database agent.
- “Explain the refund policy” routes to the knowledge base agent.
- “My order never arrived” routes to escalation.
That small layer of decision-making is what makes the thing feel alive instead of scripted.
Parallelization (Isn’t Optional)
Sequential workflows kill good products. If your agent has to query Source A, wait, summarize, then query Source B, you’ve already burned the attention budget of every impatient user (read: all of them). The teams winning right now parallelize by default. Cognition AI runs eight tool calls in parallel per turn. That cuts a 20-second round-trip to four seconds. Four seconds is the difference between “wow, magic” and “eh, it’s thinking.”
The trade-off, of course, is operational overhead. It gets token hungry, and it can become more complex to investigate after the fact. You need structured logging, clearer dependency graphs, and confidence in retries. But honestly, the same was true when we learned to build microservices. You take on orchestration complexity to buy user experience. Know your products value, so you know when it is worth the trade off.
Reflection
The first draft from an LLM is usually mediocre. Sometimes it’s wrong. Reflection solves that. You instrument the agent to critique its own work, or you let a second agent play reviewer. Producer ➝ Critic ➝ Revision. It’s the same loop I run on every article and every PRD, except now the system can do it without me hovering.
- Producer-critic pairs catch factual errors.
- Self-review prompts keep tone consistent.
- Debates merge competing answers into something sharper.
Yes, it’s slower. But when quality matters (strategy docs, legal summaries, anything that hits executives) that extra loop saves you from embarrassing yourself. Personally, I love having a two-agent party for any output to be read by customers; one that has writing guidelines and one that has output requirements. Then, let these two call each other recursively until both are happy.
Planning
Planning is the difference between “assistant” and “operator.” A reactive agent waits for orders. A planning agent looks at the goal, breaks it into steps, picks tools, and adapts when something fails. Google Deep Research doesn’t just search. It plans a research project, executes, revises, and hands you the final thread. That is roadmap thinking for machines.
Cursor really changed its product when it added the planning mode. If you haven’t tried it, I highly recommend it. It is now default for any cursor prompt to plan, make checklists. No longer do I have to run “Break down the task, make a to-do, ask questions, and only then execute” as my system prompt.
Tools Make the Work Real
An LLM without tools is just a creative intern with no browser. It can talk, but it can’t act. The minute you add tool use (function calls, API hooks, custom code) the agent stops pretending and starts delivering. Weather? API call. Database joins? SQL agent. Screenshot diffing? Vision tool. It’s the difference between ChatGPT that explains the weather and ChatGPT that checks it.
Build AI Teams, Not Lone Wolves
Single agents get you far. Teams of agents get you shipped. Planner, researcher, writer, reviewer, the exact structure we use in human organizations. They can hand off, work in parallel, even argue. SWE-Grep is a perfect example: parallel retrieval agents, synthesis agents, reflection before answers. It feels like watching a high-functioning product squad move in fast-forward.
- Planner maps the work.
- Researchers gather and score evidence.
- Writer assembles the narrative.
- Reviewer slaps the output when it drifts.
You end up with scale without chaos. Crazy.
Watch the Context Window
Context rot is real. You’ve felt it. The agent starts sharp, then forgets what you said 30 messages ago. Recursive agents fix this by splitting work into sub-problems, spinning up fresh context for each, and stitching everything back together. Think of it as a clean-mind system. One orchestrator agent keeps the mission intact while specialists dive into their own sandbox.
In the End
The best agent systems today look suspiciously like well-run teams. Planner (PM), researcher (analyst), builder (engineer), reviewer (lead), router (ops). We’re not just writing prompts anymore; we’re designing real systems. The system plans, decides, executes, checks, and ships before you finish your coffee.
You stop building chatbots. You start building workers. I think it is pretty cool and can solve legitimate real-life problems.
If you identify the right problems to solve.